Subscribe and receive the latest news from the industry.
Join 62,000+ members. Yes it's completely free.
Is Cisco’s solution ready for the future service provider data center? We tested: Data center convergence In-service software upgrades Control plane failover And more...
June 11, 2009

This report series documents the results of a Cisco IP video infrastructure, applications, and data center test. Earlier this year, following months of talks with Cisco Systems Inc. (Nasdaq: CSCO), Light Reading commissioned the European Advanced Networking Test Center AG (EANTC) to conduct an independent test of a premium network solution to facilitate advanced IP video services for service providers, enterprises, and broadcasters alike.
Having highlighted IP video applications and the service delivery network, it's logical to now consider the last piece of any media-aware network, or "medianet" – the service provider data center, the heartbeat of all the application services. (See Testing Cisco's IP Video Service Delivery Network and Video Experience & Monetization: A Deep Dive Into Cisco's IP Video Applications.)
Service providers are facing a couple of new challenges in the data center. Video on demand (VoD) and all the other video application services require a pretty substantial server farm and high-performance storage on a large scale. The quality of the data center is visible to customers in two ways: First, the service performance and flexibility; second, the service price. These are obviously conflicting goals for service providers. For this report, we have verified how far Cisco’s service provider data center solution can help to resolve some of the conflicts between price and performance. Service provider data centers are seeing rapid growth. New server farms are needed for most, if not all, the applications associated with quad-play services, in addition to the enterprise applications that are now offered. To put matters in a historical perspective the first wave of broadband access service deployments was manageable – just the AAA (authentication, authorization, and accounting) and service selection systems; the second wave added packet voice-related services; but the current wave of deploying video services requires new solutions. The traditional "new service, new server" approach that worked for a long time is not competitive any more.
Service provider data centers are seeing rapid growth. New server farms are needed for most, if not all, the applications associated with quad-play services, in addition to the enterprise applications that are now offered. To put matters in a historical perspective the first wave of broadband access service deployments was manageable – just the AAA (authentication, authorization, and accounting) and service selection systems; the second wave added packet voice-related services; but the current wave of deploying video services requires new solutions. The traditional "new service, new server" approach that worked for a long time is not competitive any more.
Now, when it comes to the ISPs' backyard, we should really be looking to large enterprise data centers for guidance. Those guys have experienced the pressures of scalability, flexibility, and total cost of operation for years already, and are (for once!) much more advanced than the average service provider.
Storage area networks (SANs) have proven their benefits in large enterprises, where they have been unanimously adopted. Computing power and storage are separated into unbundled modules that can be interconnected any-to-any – increasing flexibility in resource allocation and creating an economy of scale.
Service providers are still clinging to their direct-attached disks for service delivery to avoid adding complexity.
Our intent in the following data center tests was to find out:
Is there a risk in moving from direct-attached disks to a Cisco SAN-based solution?
What are the specific benefits of Cisco's integrated storage networking solution, compared to a plain vanilla SAN implementation?
Can any of a medianet's applications function while using network-attached disks?
A logical extension of the migration to SANs is the virtualization of computing resources – an area of new developments and a burning issue related to the industry’s move towards green IT.
Virtualization allows making more efficient use of the CPUs running on all these servers. Almost all servers spend a great deal of time running idle. They can be hosted on a single physical system, or clusters thereof, to run multiple instances of server applications (virtual servers).
The upshot? You save on the number of physical machines needed to operate a service (and also save on electricity, cooling, and the physical hardware maintenance). You also are able to run the same number of services using less space.
So what has Cisco, as a router and switch vendor, to do with data center virtualization? A lot, actually. Virtualization adds operational complexity in directing (routing, switching) network data to the physical systems running the appropriate virtual server. And a hard look at this data center solution helped us verify Cisco’s claims that they have found an elegant partnership with VMware Inc. (NYSE: VMW). (See Cisco Dreams of Data Center Unity and Cisco's Nexus Targets Data Center's Future.)
The story sounded convincing. On the slideware side of things, it should appeal to every service provider CIO or CTO: Be green, save on operational expenses (opex), have more space in the data center for future growth. But:
How did the Cisco solution work in our test?
How did the IP video applications behave using network-based disks running on virtual servers?
Is Cisco’s solution ready for the future service provider data center?
The report will shed light on just these questions. Here's a hyperlinked table of contents:
Page 3: Results: Unified Fabric
Page 5: Results: Data Center Convergence
Page 7: Results: Control Plane Failover
Page 8: Conclusions
— Carsten Rossenhövel is Managing Director of the European Advanced Networking Test Center AG (EANTC) , an independent test lab in Berlin. EANTC offers vendor-neutral network test facilities for manufacturers, service providers, and enterprises. He heads EANTC's manufacturer testing, certification group, and interoperability test events. Carsten has over 15 years of experience in data networks and testing. His areas of expertise include Multiprotocol Label Switching (MPLS), Carrier Ethernet, Triple Play, and Mobile Backhaul.
— Jambi Ganbar is a Project Manager at EANTC. He is responsible for the execution of projects in the areas of Triple Play, Carrier Ethernet, Mobile Backhaul, and EANTC's interoperability events.Prior to EANTC, Jambi worked as a network engineer for MCI's vBNS and on the research staff of caida.org.
— Jonathan Morin is a Senior Test Engineer at EANTC, focusing both on proof-of-concept and interop test scenarios involving core and aggregation technologies. Jonathan previously worked for the UNH-IOL.
Next Page: Results: Cisco's Storage Area Networks
Key finding: Two IP video applications – IP video surveillance and digital signage – worked well over Cisco's storage area network.
Service providers have been reluctant to adapt their data centers to SANs and are typically still using direct-attached disks (via SCSI, SAS, SATA, etc.). When starting our investigation of Cisco’s data center solutions we kicked things off with a view into the architecture that Cisco recommends to its customers. Direct-attached disks work well, but are typically greedy – they monopolize their servers and are not very accommodating to sharing resources. On the other hand, they work. This is not an argument that can easily be discarded, especially after so many years of usage and best practices.
SANs offer two distinct benefits to service providers: Efficient use of storage capacity and cost savings in the long term. In order to enjoy these benefits we had to make sure that Cisco’s IP video applications could actually run over a SAN by moving the attached disks to a network-based storage solution. If the applications work over the network storage, efficiency could increase and the number of physical disks that a service provider needs to maintain could decrease, while maintaining the same level of service and resiliency.
Cisco first took us on a tour of its data center design, shown in the figure below, which included the MDS 9500 series of Fiberchannel directors and Nexus 5000 for Fiberchannel access. We verified that the two applications that Cisco chose for the test – IP video surveillance and digital signage (described in our previous test report) – were actually working with shared, SAN-attached storage. In addition, we actually used the video surveillance camera to monitor and record our own test – we ended up with a nice video clip souvenir of our investigation. The IP video applications we observed worked just fine over the SAN in the topology depicted above. Clearly there are other IP video applications from Cisco that we did not see in this configuration, but we trust that Cisco supports these as well. The move to SAN is also a clear storage efficiency increase. A single network-attached disk could be used to support several servers and applications, hence increasing the utilization of the disks and preventing idle disks from consuming energy and space without being used. The move to SAN also facilitates the next two possibilities for service providers: Fibre Channel over Ethernet and virtualization. Both are discussed in the next two test case results.
The IP video applications we observed worked just fine over the SAN in the topology depicted above. Clearly there are other IP video applications from Cisco that we did not see in this configuration, but we trust that Cisco supports these as well. The move to SAN is also a clear storage efficiency increase. A single network-attached disk could be used to support several servers and applications, hence increasing the utilization of the disks and preventing idle disks from consuming energy and space without being used. The move to SAN also facilitates the next two possibilities for service providers: Fibre Channel over Ethernet and virtualization. Both are discussed in the next two test case results.
Next Page: Results: Unified Fabric
Key finding: With the Nexus 5000, Cisco converges Ethernet and storage traffic, reducing the number of required ports to the server by 66 percent.
SANs that make use of Fibre Channel (FC) technology typically require that one or more cables be run to each server purely for FC interface connections. In addition, network cables (such as Ethernet) must be connected between the servers and the local area network (LAN) switches. Servers, after all, must receive requests from the client sitting on the network and make the appropriate data look-up to the SAN via FC before answering the clients.
This requires two sets of cables and ports – network and data. Cisco’s solution takes advantage of Fibre Channel over Ethernet (FCoE) technology and converges SAN and LAN traffic over a single link, thereby reducing server port count in the data center.
Our two main targets for these tests were to:
Verify that Cisco’s IP video applications are able to function over SAN infrastructure
Verify that no negative effect is seen on the applications when additional traffic is run over the same infrastructure
To validate the points above, Cisco ran two IP video applications over the network: digital signage and IP video surveillance applications (both described in our first test report). The clients for these services were configured to access the servers over the network and to read or write files from the SAN disks.
We used the Spirent Communications plc tester to generate additional network and storage load on the system:
First, Spirent TestCenter was configured to transmit 6 Gbit/s of Ethernet traffic and 4 Gbit/s emulated FCoE traffic bidirectionally between two FCoE-capable 10-Gigabit Ethernet ports, each connected to the same switch that was serving the IP video applications – the Nexus 5000.
Next we transmitted continuous HTTP Get requests from a Spirent Avalanche to the same server running both applications. The requested file was actually the video file used for the Digital Signage application. This way we were sure that the file really needed to be accessed from the SAN disks and was not on the server itself.
 We monitored the application behavior for degradation in service quality or noticeable video effects all through the tests.
We monitored the application behavior for degradation in service quality or noticeable video effects all through the tests.
The results were positive on all accounts:
The Spirent TestCenter was able to establish a Fibre Channel login on the Nexus 5000 and transmit line-rate Ethernet and Fibre Channel traffic on a 10GE interface without any loss and with average latency of 3.35 ms.
Spirent Avalanche successfully retrieved the requested file, proving that the server was able to receive and process Ethernet traffic from the LAN, such as an HTTP Get request in this scenario, then make a Fibre Channel lookup for the file requested over the same physical Ethernet link.
Throughout the course of the test, no interruption visible to the human eye was witnessed on the digital signage and IP video surveillance applications.
The test confirmed Cisco’s expectations: The Nexus 5000 worked in this single-server scenario without showing any degradation in service quality. In a real-world deployment it is expected that many more servers would be attached to the Nexus 5000 – the potential array of servers is described in the previous report, where we discussed user experience and monetization.
In addition, a clear benefit of the move to FCoE could be shown using a back-of-the-envelope calculation: In a traditional Fibre Channel environment, two Ethernet ports would have been required for each service (for resiliency) plus two SAN connections, using six ports in total. Here only two ports were needed – a 66 percent reduction in server port count.
Next Page:Results: Virtual Machine Relocation
Key finding: A solution using Cisco's Nexus 1000V virtual switch and VMware’s Vsphere allows for a virtual machine-run process to be moved from one physical server to another with negligible interruption observable to the end-user.
One of the main advantages of virtualization is flexibility. If the application runs out of CPU resources on a specific physical server, the administrator can move a few virtual hosts to another physical server and move on. In practice, network administrators have to go through some pain when moving virtual servers around, because the Ethernet port configuration needs to be moved simultaneously.
To solve the above problem Cisco introduced a smart virtual switch that can do the work for the administrators – the Nexus 1000V. The idea is that the virtual switch will manage the connectivity of each virtual server in the physical server cluster. The Nexus 1000V is a Cisco Nexus switch very similar to others in the sense of code releases and CLI. However, there is one major difference: the Nexus 1000V is not a piece of hardware but, rather, software. Instead of physically plugging a cable into a server and switch, you virtually connect a virtual server to a port on the virtual switch.
Finally – and this is where the flexibility aspect comes in – the Nexus 1000V process is distributed among the different physical servers and their respective management servers. This allows the administrator to move a process from one physical server to another. Suppose an admin would like to upgrade a piece of hardware on one of his servers, but sees that several clients are currently using the server. Not only does the admin not have to disconnect the clients in order to relocate these processes to a second server, he or she also does not have to reconfigure the Ethernet switch.
Now, if this works properly, it can save the administrator a lot of configuration time and prevent mistakes.
Our test was to verify two main points Cisco claimed:
The ability of the solution to migrate a virtual machine-run process from one physical server to another with negligible interruption observable to the end-user. Not only did we expect to see that the whole virtual server move could be done across physical servers, but also that the move would not require anything more than a single command without any port profile configuration performed on the Nexus 1000V.
The second point was to actually verify that the two Cisco applications were able to run on virtual servers.
We started with Virtual Machine Host 2 running the two applications we used in the previous test (IP video surveillance and digital signage) and Virtual Machine Host 1 powered off. Both applications were running on the same virtual server. We then powered on Virtual Machine Host 1. Once both servers were powered on, we used VMware’s Vsphere to relocate an entire virtual machine to Virtual Machine Host 1. Once the relocation process was completed, Virtual Machine Host 2 was powered down. After each step in the test procedure we recorded a status check and captured both the management system and the Nexus 1000V configuration. Throughout all power cycles the applications remained stable, proving the relocation of their processes. Additionally, diagnostics on the Nexus1000V showed that the management system successfully re-associated the virtual port from one module (Virtual Machine Host, Vsphere server) to another, without the need of editing the port configuration. Throughout the entire test process, no disruption of the running applications was observed.
After each step in the test procedure we recorded a status check and captured both the management system and the Nexus 1000V configuration. Throughout all power cycles the applications remained stable, proving the relocation of their processes. Additionally, diagnostics on the Nexus1000V showed that the management system successfully re-associated the virtual port from one module (Virtual Machine Host, Vsphere server) to another, without the need of editing the port configuration. Throughout the entire test process, no disruption of the running applications was observed.
Having a smart network that would react by itself to moves should be filed under good news for every network administrator. Here the move was actually done using Vmware’s Vsphere solution, and the network automatically responded – an obvious benefit over the manual process. It is also interesting to see Cisco forging into the virtualization space with a switch that really “feels” like any of the other Nexus boxes. If we had not insisted on seeing every box, we could have easily been tricked into thinking that we were on a physical machine.
Next Page:Results: Data Center Convergence
Key finding: Using the Virtual Port Channel and Virtual Device Context features, Cisco reduces failure times in the data center to less than a second.
Now that we had tested different components and features of the data center, it was time to test Cisco’s data center in the context of a full IP video "medianet." This meant using the traffic profile of both business and residential applications to test the IP Video Service Delivery Network. We sent emulated Digital Signage, TelePresence, and Video Surveillance traffic into the network through the Nexus 5000. IP video, Internet, and VoIP traffic were attached to the network via the Cisco Nexus 7000 as depicted in the image below. To round out the service offering, VoD and pay-per-view traffic was also transported in the network, but these services entered the network via the ASR 9010 and did not traverse the data center. Cisco designed its IP video-centric data center to address the key concern service providers have – avoiding a single point of failure. In the Service Delivery Network topology, there are customers from a wide range of distant locations accessing a single data center. It is very important to install and configure the proper redundancy mechanisms in the data center in order to avoid upsetting, not merely one of your customers, but all of them.
Cisco designed its IP video-centric data center to address the key concern service providers have – avoiding a single point of failure. In the Service Delivery Network topology, there are customers from a wide range of distant locations accessing a single data center. It is very important to install and configure the proper redundancy mechanisms in the data center in order to avoid upsetting, not merely one of your customers, but all of them.
One such redundancy mechanism often seen in data centers is the IEEE’s Link Aggregation Group (LAG, defined in IEEE 802.3ad). This mechanism allows the network administrator to bind several physical links together in a group. When links within the group fail, the other, still active links, will then carry the traffic, as long as there is enough capacity in the group. This solves the issue of potential links between two switches failing – however, what happens when a complete switch fails?
Using the “traditional” LAG mechanism, we would experience complete loss of services. To solve this issue and therefore increase the level of resiliency in the data center, Cisco used a new feature available in the latest Nexus switches code release NX-OS 4.1(5) that is similar to LAG, but is configured among three devices.
Cisco calls this feature Virtual Port Channel (VPC). VPC is a virtual port group, which can be distributed across multiple devices, allowing the full bandwidth capacity of multiple links to be used. In addition, the physical (hardware) and logical (OS) resources on the Nexus 7000 switches can be virtualized where any set of ports can become members of a Virtual Device Context (VDC, a virtual switch). These two complementary configurations were used to virtualize all business and residential traffic in the test. The figure below depicts the virtual port channels configured in the test: We tested that the system could effectively provide resilient connectivity to the data center by sending the same traffic we used in our service delivery network tests. Our goal was to verify that if a link between two Nexus devices failed, the traffic being carried over the failed link would still flow using a different path.
We tested that the system could effectively provide resilient connectivity to the data center by sending the same traffic we used in our service delivery network tests. Our goal was to verify that if a link between two Nexus devices failed, the traffic being carried over the failed link would still flow using a different path.
Three emulated business applications were attached to the network on the Nexus 5000 switch using four 10-Gigabit Ethernet interfaces. Cisco configured each incoming 10-Gigabit Ethernet port on the Nexus 5000 to accept traffic for a single business service. The Nexus 5000 was then configured to split all traffic for each service evenly to each downstream Nexus 7000.
In essence, a VPC with a link to each Nexus 7000 was configured for each data center business service, with the exception of telepresence, which used two VPCs for this test. This configuration would be reasonable for an operator that knows its data center traffic utilization very well. Since trending and capacity planning are best-practice in service provider networks and data centers, we accepted the configuration. Cisco explained that if a single link in the VPC failed, the other link would then transport the full load for that service, rerouting to the proper Nexus 7000 device via the links between the two Nexus 7000 devices. The diagram above displays this forwarding behavior.
Our initial plan was to fail all links on one side of the data center and verify that the other side could maintain the service and perform the switchover. We were informed by the Cisco engineering team that recovery from such multiple failure was not possible, and so we were left with the usual failure scenario – a single link.
We tested the virtual port channel’s ability to recover from a group member's single-link failure by using the full service delivery network traffic profile and disconnecting a single downstream link from the Nexus 5000. After understanding the way Cisco configured the data center, we expected only one service to be affected. Cisco’s claim was that the service would recover from the broken link in less than one second. The figure below shows the link that was disconnected for the test simulating the link failover in the data center. EANTC’s standard failover test procedure calls for repetition of the tests three times in order to collect a minimum statistical significance in the results. In this particular case, due to inconsistency of the results in one test run, we decided to perform an additional two test runs, bringing us to five test runs in total (or actually five failover test runs and five recovery test runs).
EANTC’s standard failover test procedure calls for repetition of the tests three times in order to collect a minimum statistical significance in the results. In this particular case, due to inconsistency of the results in one test run, we decided to perform an additional two test runs, bringing us to five test runs in total (or actually five failover test runs and five recovery test runs).
The link we abused was serving exactly four business ports attached to the uPE1. We expected that when we failed the link the business ports attached to the second uPE would not show any negative effect, and indeed the results showed almost that. A few frames were still lost on ports that we did not expect, which Cisco explained was an effect of the hashing process used. The graph below shows the highest out-of-service time recorded on a single port amongst the four ports where we expected to lose traffic. In fact, the loss observed across these four ports was consistent as to beexpected, never differing by more than 20 lost frames. The news was positive regardless. All test runs on all ports showed that the recovery times never exceeded the one second claimed by Cisco.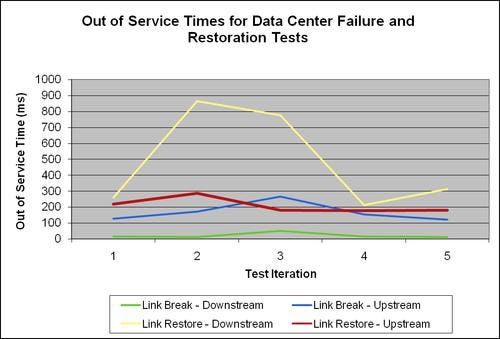 In the world of backbone routing, the results we show above are perhaps disheartening. As an update to the available data center resiliency mechanisms, such as various Spanning Tree Protocols and Link Aggregation Groups, Cisco claims that the results shown here are an improvement. From our testing experience, Spanning Tree Protocols could indeed require seconds to converge, which acknowledges Cisco claims and is clearly another valid and unique data center resiliency mechanism for service providers.
In the world of backbone routing, the results we show above are perhaps disheartening. As an update to the available data center resiliency mechanisms, such as various Spanning Tree Protocols and Link Aggregation Groups, Cisco claims that the results shown here are an improvement. From our testing experience, Spanning Tree Protocols could indeed require seconds to converge, which acknowledges Cisco claims and is clearly another valid and unique data center resiliency mechanism for service providers.
Next Page: Results: In-Service Software Upgrade (ISSU)
Key finding: Major and minor hitless software upgrades can be accomplished on Cisco's Nexus 7000 series switches.
Generally, most people who are not IT-related understand the concept of a software upgrade, and accept the need for them to exist. If not, after a short discussion with a network administrator one would know how his job consists of hearing about issues from his colleagues, and receiving new code from the vendor in order to resolve them. Most people who are not IT-related are also familiar with the chore of having to reboot their PCs once patches or upgrades have finished installing.
That rebooting becomes a much bigger issue when it involves a network device that is servicing millions of users. Cisco understands this issue and has developed a solution, which they claim would enable major and minor code upgrades to incur no negative effect on the users. In this test we measured the out-of-service time induced on the traffic when both major and minor software upgrades were performed on the Nexus 7000.
In order to perform a software upgrade on the Nexus 7000 we needed multiple versions of the NX-OS operating system – the system used on Cisco’s Nexus switches.
Cisco provided three code versions for the focus of the test:
The Nexus 7000: 4.0(4)
The Nexus 7000 4.1(3)
The Nexus 7000 4.1(5)
The 4.0 and 4.1 operating system codes are considered by Cisco (and to the best of our understanding) major releases.
A new feature used in our testing, VPCs (Virtual Port Channels), were first introduced in the 4.1 code. The difference between 4.1(3) and 4.1(5) is considered minor and represents a set of bug fixes. For the minor software upgrade we ran the full service delivery network traffic profile and measured loss induced by upgrading the code on the Nexus 7000. The caveat of the major upgrade was the lack of support for VPC, which was required to transport traffic from the Nexus 5000 in the test setup. We accepted that for the major upgrade we would run all traffic except telepresence, digital signage, and IP video surveillance, leaving IP video, VoIP, and Internet traffic traversing one Nexus 7000, and VoIP and Internet traffic traversing the other Nexus 7000. It was clear that the two switches would still have more than enough frames to deal with while also being upgraded.
We ran each instance of this test for approximately 25 minutes, allowing for enough time for the code upgrade to finish and verifying that the new code had truly been installed on the device. We let the test traffic continue running for two extra minutes to make sure that the upgrade was not only successful, but that the switch was stable afterwards.
We stopped traffic between each iteration and measured frame loss. First we upgraded each Nexus 7000 from 4.1(3) to 4.1(5), one device at a time, and recorded zero frames lost. This was the minor software upgrade. Following these two upgrades we stopped traffic in order to reload each Nexus 7000 with 4.0(4) code to perform the major upgrade – 4.0(4) to 4.1(5). This major upgrade was also performed on one Nexus 7000 at a time, for a total of four test iterations.
One way that we verified both upgrades was through witnessing the device switch from one switch engine to the other, as this is the method used to upgrade the device without loss – one switch engine at a time. We, of course, also checked the versions of running code through CLI commands both before and after each test. The major upgrade was additionally verified through the attempts of certain commands that did not exist on the previous operating system.
Throughout both upgrades we witnessed zero packet loss. After the last major upgrade was completed, we added the business services from the Nexus 5000, still witnessing no loss. We conclude that data center administrators can upgrade their Nexus 7000 gear even during peak hours without users experiencing the negative impact of dropped packets. This obviates the need for the administrator to come in at night or during the weekend in order to do such upgrades, which in turn avoids an extra cost to the provider.
Next Page: Results: Control Plane Failover
Key finding: The Nexus 7000 kept running a full traffic profile, with zero packets lost, when a linecard with an active control plane was physically removed from the switch.
In the previously released IP Video Service Delivery Network report we detailed a series of control plane failover tests performed on Cisco's CRS-1 and ASR 9010 routers. In addition to these core and aggregation routers, Cisco asked that we run this test on the Nexus 7000 in the data center.
To do this, we repeated the same procedure used when testing the CRS-1 and ASR 9010 as described in the previous article, consisting of running the full traffic profile under steady network conditions and physically removing the card with the active control plane.
Throughout three full repetitions of the test we observed zero packets lost, indicating that a control plane failure in the Nexus 7000 would not induce a negative impact on the end user. That’s another useful piece of news for the service provider operating a data center. All he needs are two control planes in each Nexus 7000 switch for both control plane failure conditions and hitless software upgrade – and for that he gets many more good night sleeps.
Next Page: Conclusions
The tests documented in this report showed us that Cisco has a clear plan for its data center products. Service providers have to expand their service offerings to both residential and business customers to stay competitive and to increase their customer retention. While the network is the backbone of these IP video deployments, the data center is the brains. Without content, the backbone is going to be a pretty boring place.
So service providers, having to accommodate the plethora of services and the disk-space-hungry applications, must extend their data centers, and we saw that Cisco is positioned to support their needs. The Cisco story here is clear: First migrate to storage area networks and run your applications over the network. Then, since you’re already using SAN, why not use some of the virtualization options in the market and, while you are at it, be "greener." Next, you can make the lives of your operations staff simpler and, with two control plane modules in your data center switches, you will be able to enjoy hitless software upgrades and won't lose valuable services revenues when the control plane fails.
IP video applications are much less accommodating than best-effort Internet applications. A failure anywhere in the path between the application server and user is a potential cause for a torrent of calls to the support hotline. It is reassuring to see that Cisco has considered the complete path in its IP video solution.
An operator can never know who is watching an IP video program in the middle of the night, exactly when the “maintenance window” is open. These days are now gone and they are not coming back. The services have to be up and running, and the subscribers or businesses depending on them will show much less sympathy to the provider having to upgrade code or experiencing failures. So Cisco’s high-availability options seem to fit well with the service requirements.
We would have loved to spend more time with the data center systems and run them through rigorous FCoE and Ethernet tests. With Spirent’s recent Virtual TestCenter announcement (sadly, a month too late for our testing) one can imagine a whole new set of virtualization performance and scalability testing. We sure hope that in the next testing campaign we will get to explore these aspects in depth.
— Carsten Rossenhövel is Managing Director of the European Advanced Networking Test Center AG (EANTC) , an independent test lab in Berlin. EANTC offers vendor-neutral network test facilities for manufacturers, service providers, and enterprises. He heads EANTC's manufacturer testing, certification group, and interoperability test events. Carsten has over 15 years of experience in data networks and testing. His areas of expertise include Multiprotocol Label Switching (MPLS), Carrier Ethernet, Triple Play, and Mobile Backhaul.
— Jambi Ganbar is a Project Manager at EANTC. He is responsible for the execution of projects in the areas of Triple Play, Carrier Ethernet, Mobile Backhaul, and EANTC's interoperability events.Prior to EANTC, Jambi worked as a network engineer for MCI's vBNS and on the research staff of caida.org.
— Jonathan Morin is a Senior Test Engineer at EANTC, focusing both on proof-of-concept and interop test scenarios involving core and aggregation technologies. Jonathan previously worked for the UNH-IOL.
Back to Introduction
You May Also Like


_International_Software_Products.jpeg?width=300&auto=webp&quality=80&disable=upscale)






